Documentation Index
Fetch the complete documentation index at: https://domoinc-jkreitzman-patch-1.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
はじめに
Domoの自動機械学習(AutoML)ツールにより、機械学習は誰もが理解できるものになりました。 AutoMLは、Amazon SageMaker Autopilotと連携して、提供するデータにもとづいて機械学習モデルを訓練し、任意のDomo DataSetで何百もの訓練ジョブを起動して、タスクに最適なモデルを見つけます。その後、Magic ETLの[AutoML推論]タイルを使用して、Domo DataSetに モデルを展開 できます。 AutoMLの動作を確認するには、 こちらの動画 を参照してください。
を参照してください。

- 必要な許可
- AutoMLツールを有効にしてアクセスする
- AutoMLのデータを準備する
- AutoMLを使用する
- Magic ETLの[AutoML推論]タイルを使用して予測を生成する
必要な許可
AutoMLにアクセスするには、次の許可が有効になっているシステム権限またはカスタマイズされた権限が必要です。- AutoMLを有効にする — AutoMLモデルを訓練し、 AutoML推論の操作を含むDataFlowを実行できます。
AutoMLツールを有効にしてアクセスする
AutoMLツールにアクセスするには、まずAutoMLツールを有効にする必要があります。 コンサンプション契約を締結しているユーザーはデフォルトでAutoMLを使用できます。 コンサンプション契約を締結していないユーザーの場合、AutoMLはオンデマンドで有料で使用することができます。AutoMLを有効にするには、Domoアカウントチームにお問い合わせください。 AutoMLを有効にした後は、Data Centerの任意のDataSetの詳細ビューに移動してから [AutoML] タブに移動することで、AutoMLにアクセスできます。
AutoMLのデータを準備する
以下のチェックリストを使用して、AutoMLツール用にデータをクリーンアップし、準備します。以下の原則に従うと、AutoMLで効果的なモデルを訓練できる可能性が高くなります。パートI:データ構造
DataSetを構造化するには、以下の項目を完了します。- 1つのDataSet — データは1つのDataSetにまとめてください。DataSetには、出力変数(予測する変数)と入力変数(出力変数に影響を与えると予想される、予測に使用する変数)の両方を含める必要があります。入力変数は、機械学習の分野では一般的に「特徴量」と呼ばれます。
- 結果を特定する — DataSetには1つの出力列のみを含めてください。
- 分析の単位 — 各行はビジネス上の課題の記録の1つを表す必要があります。 例えば、どの商談が終了するかを予測する場合、各行は最初から最後まで特定の1つの商談の詳細を示し、各商談の結果を出力列に表示しなければなりません(成功か失敗か)。
パートII:データの準備
DataSetを構造化した後は、DataSetの処理前に以下の項目を完了します。- 不足しているデータを処理する — 値が不足している行を除外するか、列の平均値や中央値を取るなどのインテリジェントな方法で値を入力してください。
- 多重共線性を確認して削除する — データに冗長性がないか監視し、冗長性をなくしてください。 例えば、「売り上げ」と「収益」の2つの予測列があり、「利益」列を予測したいとします。 「売り上げ」と「収益」はほぼ同じ量、ビジネスに入ってくるキャッシュフローを表しているので、どちらか一方だけを含めるべきです。 両方の列を使用すると、いくつかのアルゴリズムで数値的な安定性の問題を引き起こす可能性があります。DataSetでは、予想外に高い相関関係にある列があることが一般的なので、列間の関係を可視化したり、統計的に相関関係のテストを行うことが有効です。 冗長データを除外したら、このリストの次の項目に移動します。
- 関連する列のみを含める — 出力変数に影響を与えないと思われる列はすべて除外してください。IDと未加工データの列はこのカテゴリーに入ることが多いです。 このプロセスについて、またこのデータは予測時に知ることができるであろうことを正確に表しているかということを考えてください。
-
外れ値/レバレッジポイント — 既知の外れ値を削除してください。外れ値は統計テストか既知の経験から判断できます。
例えば、既知の異常により1週間の売り上げが不自然に増加した場合、このサンプルをDataSetから削除するのが一番です。外れ値の特定と処理の詳細については、 こちら
 を参照してください。
を参照してください。
パートIII:特徴エンジニアリング
データをどのように表現すればベストか検討します。この処理は「特徴エンジニアリング」と呼ばれます。AutoMLは基本的な特徴エンジニアリングを行ってくれます。 例えば、値「M」と「F」を「0」と「1」として「性別」列をエンコードします。 これにより、課題に関してあなたが既に持っている知識をさらに活用することができます。よくある特徴エンジニアリングの例としては、10-22-2020のような未加工データを曜日「木曜日」に変換することが考えられます。これは、曜日と対応する可能性のあるパターンをモデルに学習させることができるため、より有効な表現になります。以下に一般的な特徴エンジニアリング戦略を2つご紹介します。- ビニング — 数値データに意味のあるカテゴリーが存在する場合は、離散的な「ビン」を作成することを検討してください。 クレジットカードのスコアシステムが良い例です。 FICOクレジットスコアは連続した数値(0~800)を提供しますが、意思決定を簡単にするために、銀行はしばしばビンや階級を作成します。例えば、クレジットスコアが750以上の場合は「優良」、700~749の場合は「良好」となります。 課題に自然な階級がある場合は、データでエンコードすると便利かもしれません。また、時系列データもビニングによって操作できます。複数年の日付を週番号にビニングすることができます。
- データ削減 — 良いモデルでは、データを説明する特徴量の数が最小限になります。可能な限り、冗長または重要でない列を削除してください。無意味な機能は、モデルにノイズを発生させます。
AutoMLを使用する
インスタンスでAutoMLを 有効 にした後は、2つのAutoML使用フェーズがあります。AutoML訓練ジョブを起動するというフェーズと、モデルを展開するというフェーズです。- AutoML訓練ジョブを 起動 して、データに固有の複数の機械学習モデルを生成します。1つを選択します。
-
Domo DataSetで選択したモデルを
展開 し、Magic ETL DataFlowの[AutoML推論]タイルを使用して予測を生成します。
注記: AutoMLを試すためのサンプルDataSetは、 こちら
 からダウンロードしてください。サンプルDataSetには、電話会社の顧客の解約状況に関するデータが含まれています。このDataSetをコンピューターにダウンロードし、新しいDataSetとしてDomoインスタンスにアップロードします。
からダウンロードしてください。サンプルDataSetには、電話会社の顧客の解約状況に関するデータが含まれています。このDataSetをコンピューターにダウンロードし、新しいDataSetとしてDomoインスタンスにアップロードします。
AutoML訓練ジョブを起動する
AutoML訓練ジョブを起動するには、以下の手順に従います。このジョブ では、データに固有の複数の機械学習モデルを生成し、選択できます。-
Data Centerで、訓練するDataSetの詳細ビューに移動し、 [AutoML] タブに進みます。

-
[利用を開始] を選択します。

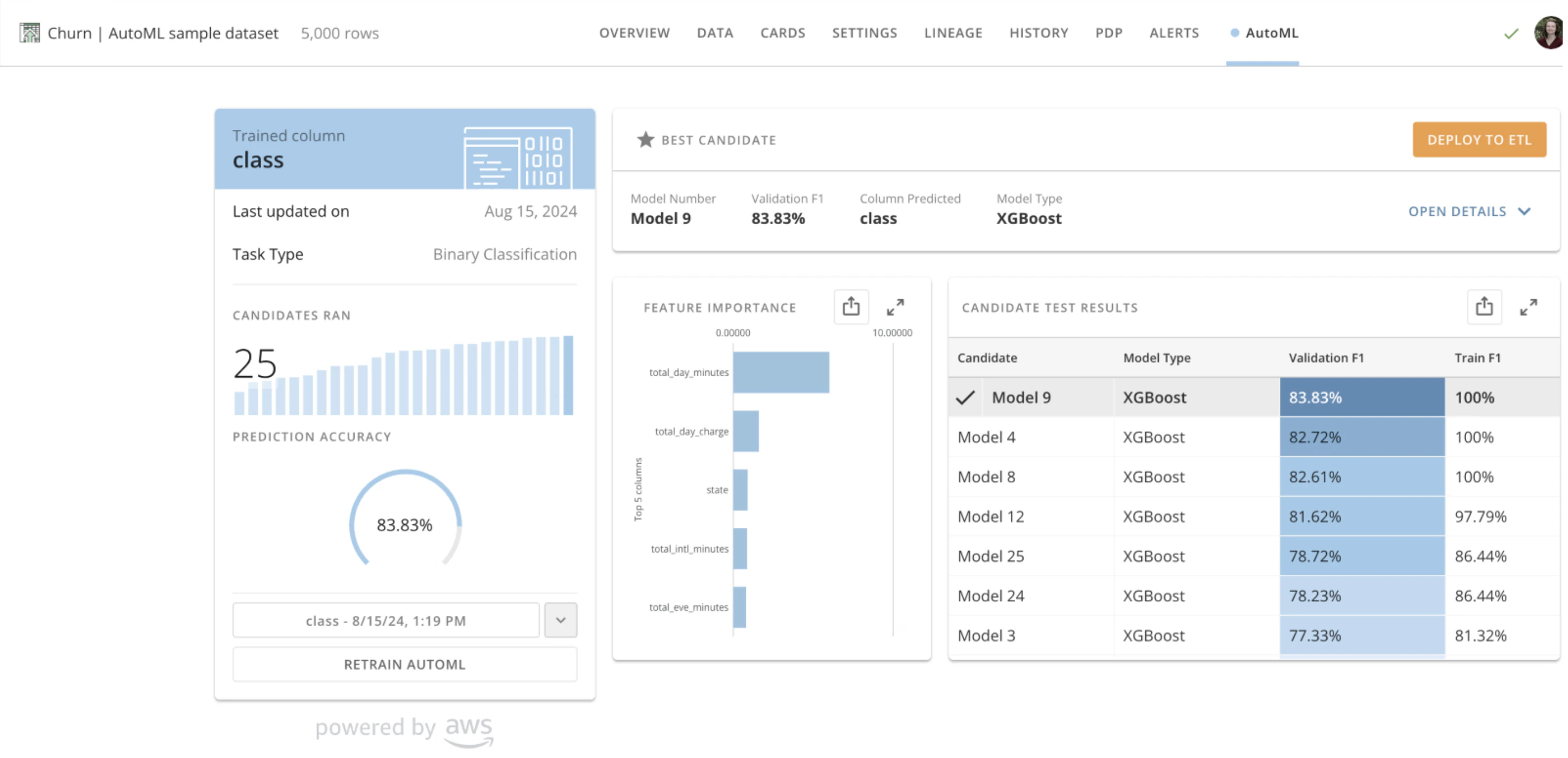
- 表示されるモーダルで、 [予測する列] ドロップダウンを使用して、機械学習モデルを予測するための訓練を行う出力列を選択します。 注記: サンプルDataSetを使用している場合は、「class」列を選択します。
- (条件付き)指定するタスクを知っている上級ユーザーでない限り、 [タスクタイプ] ドロップダウンは[自動(推奨)]に設定しておきます。
-
処理の準備ができたら、 [訓練を開始] を選択します。
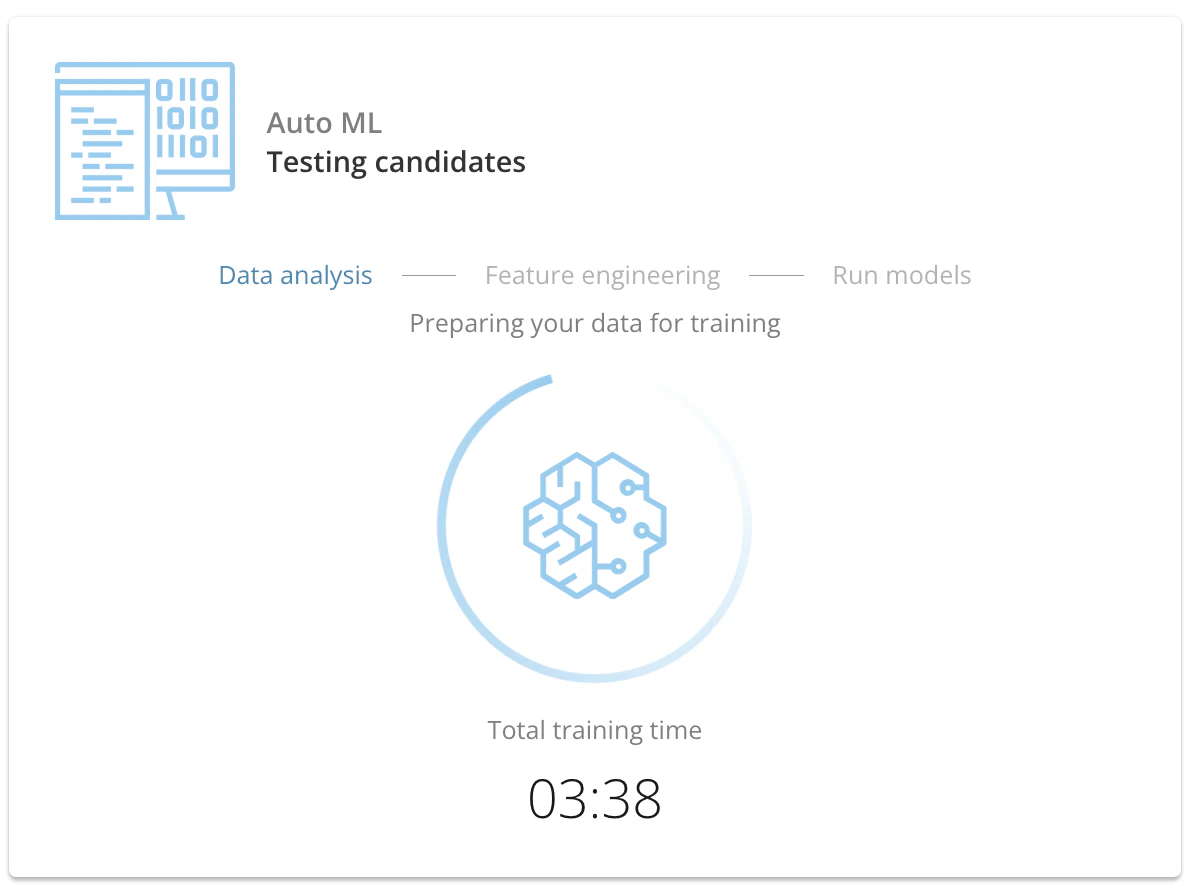
[合計訓練時間] カウンターの付いた画面が、AutoMLがデータを使用して機械学習モデルを訓練およびテストしているときに表示されます。AutoMLは、具体的には次の3つの段階を実行します。

- データ分析
- 特徴エンジニアリング
- 実行モデル

Magic ETLの[AutoML]タイルを使用して予測を生成する
Magic ETL DataFlowの[AutoML推論]タイルを使用して、選択したAutoMLモデルをDomo DataSetで展開するには、以下の手順に従います。[AutoML推論]タイルでは、以前訓練したAutoML機械学習モデルを選択して使用し、入力DataSetの各行の予測(推論)を行うことができます。- AutoML機械学習モデルの訓練に使用したDataSetの詳細ビューに移動し、 [AutoML] タブに進みます。
-
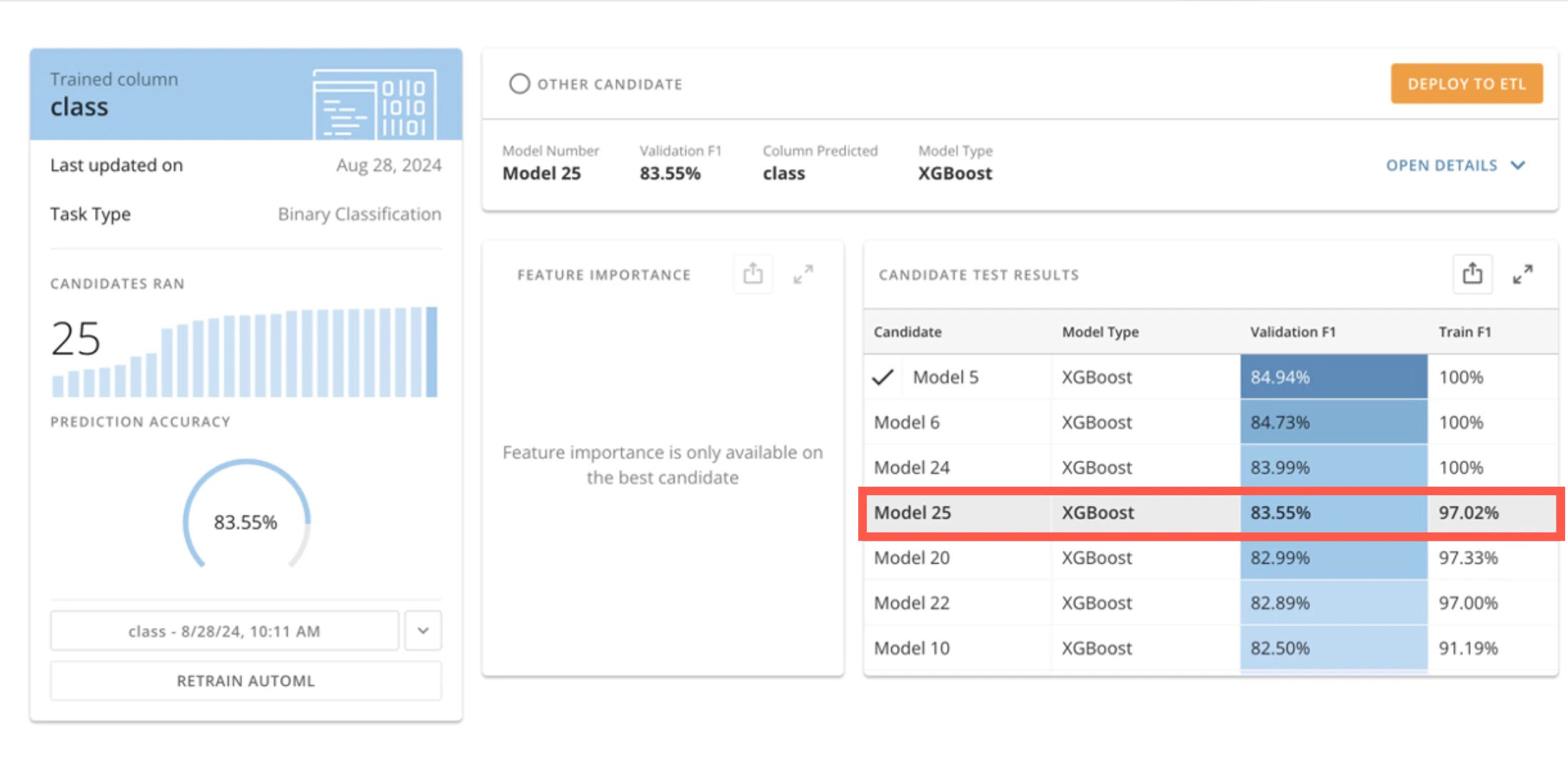
モデルの概要 ページの [候補テスト結果] で、[AutoML推論]タイルでの予測に使用するモデルを選択します。選択したモデルはグレーでハイライト表示されます。
この例では、「Model 25」が選択されています。
-
[ETLにデプロイする] を選択して、選択したモデルを展開し、Magic ETLインターフェースを開きます。
 注記: AutoMLモデルを展開するには、新しいMagic ETL DataFlowを開き、[AutoML推論]タイルをキャンバスにドラッグしてタイルを設定する方法もあります。ただし、この方法でモデルを展開する場合は、システムによって「ベストの候補」と見なされたモデルのみを使用できます。「ベストの候補」と見なされたモデルは、 モデルの概要 ページの [候補テスト結果] のリストの先頭に表示されます。
注記: AutoMLモデルを展開するには、新しいMagic ETL DataFlowを開き、[AutoML推論]タイルをキャンバスにドラッグしてタイルを設定する方法もあります。ただし、この方法でモデルを展開する場合は、システムによって「ベストの候補」と見なされたモデルのみを使用できます。「ベストの候補」と見なされたモデルは、 モデルの概要 ページの [候補テスト結果] のリストの先頭に表示されます。 -
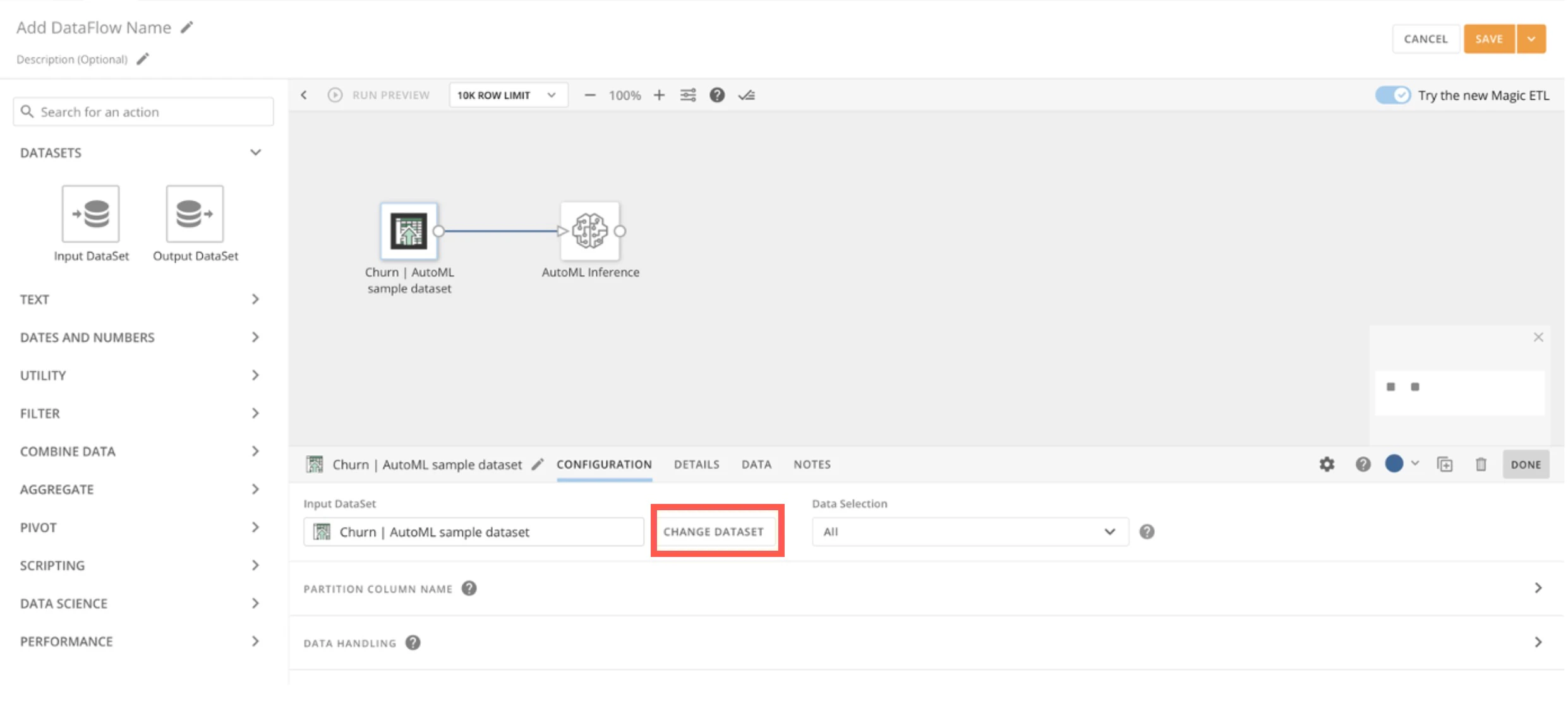
Magic ETLインターフェースのDataFlowには、[入力DataSet]タイルと[AutoML推論]タイルが事前に配置されています。 [入力DataSet]タイル > [DataSetを変更] を選択して、予測の生成に使用するDataSetを接続します。
-
(オプション)[AutoML推論]タイルを設定すると、 [予測列に名前を付ける] が事前に入力されています。この列には別の名前を選択できます。

- 出力DataSetを接続して名前を付ける
-
DataFlowに名前を付け、 展開 (下向き矢印アイコン)> [保存して実行] を選択します。
生成される出力DataSetには、入力DataSetのすべての列と(前述の 手順5 で名前を付けた)予測を含む列が含まれます。
